
Tekstin samankaltaisuus on todella hyödyllinen luonnollisen kielen (NLP) käsittelyn työkalu. Tekstin samankaltaisuudella mitataan, kuinka paljon kahden tekstin merkitys tai sisältö eroaa toisistaan. Digitaalisessa maailmassa samankaltaisuuden mittaamisella on monta sovellusta. Yleisimpiä käyttötapauksia ovat plagioinnin havaitseminen, asiakirjojen luokittelu, tiedonhaku ja kielikäännökset (Van Otten 2022).
Tripathy (2024) määrittää kaksi samankaltaisuustyyppiä: leksikaalinen, joka mittaa kahden tekstien samankaltaisuutta sanajoukkojen läheisyyden perusteella, ja semanttinen, joka luo kvantitatiivisen mittarin kahden sanan tai lauseen merkityksen läheisyydestä. On olemassa useita koneoppimismalleja tekstin samankaltaisuuden mittaamiseen. Suosituimmat niistä muun muassa ovat kosinien samankaltaisuus (Cosine Similarity) ja Levenshteinin etäisyys leksikaaliseen samankaltaisuuden mittaamiseen. On olemassa myös kontekstuaalisia kielimalleja ja Sentence Transformers -malleja semanttisen samankaltaisuuden mittaamiseen.
Sentence Transformerit ovat avoimen lähdekoodin esikoulutettuja malleja. Ne ovat ladattavissa Hugging Facelta, joka on tunnettu NLP-mallien ja -sovellusten kehittäjä. Fillion (2022) tiivistää kahden tekstin semanttisen samankaltaisuuden laskemisprosessia Sentence Transformers -mallin avulla kahteen vaiheeseen. Vaiheet ovat tekstin muuttaminen numeeriseen vektorimuotoon (embeddings) ja vektorien samankaltaisuuden laskeminen esimerkiksi kosinin samankaltaisuusmetriikan avulla.
Alla on esimerkki Pytonilla toteutetun tekstin samankaltaisuuden laskemisesta Sentence Transformer -mallia MiniLM-L6-v2 hyödyntäen. Ennen tekstin käsittelyä on asennettava sentence_transformers–moduuli ja ladattava SentenceTransformer-kirjasto. Tämän jälkeen voidaan rakentaa malli ja aloittaa varsinainen käsittely, jolloin teksti muutetaan numeerisen vektorimuotoon (embeddings). (Fillion 2022.) Kuva 1 esittää tämän vaiheen sekä käsiteltävät lauseet.

Seuraavaksi voidaan siirtyä toiseen vaiheeseen eli vektoreiden samankaltaisuuden laskentaan. Kuva 2 näyttää laskutuloksena saadun samankaltaisuusmatriisin, jossa kaikki ensimmäisen ja toisen listan (em_1 ja em_2) vektorit vertaillaan keskenään.
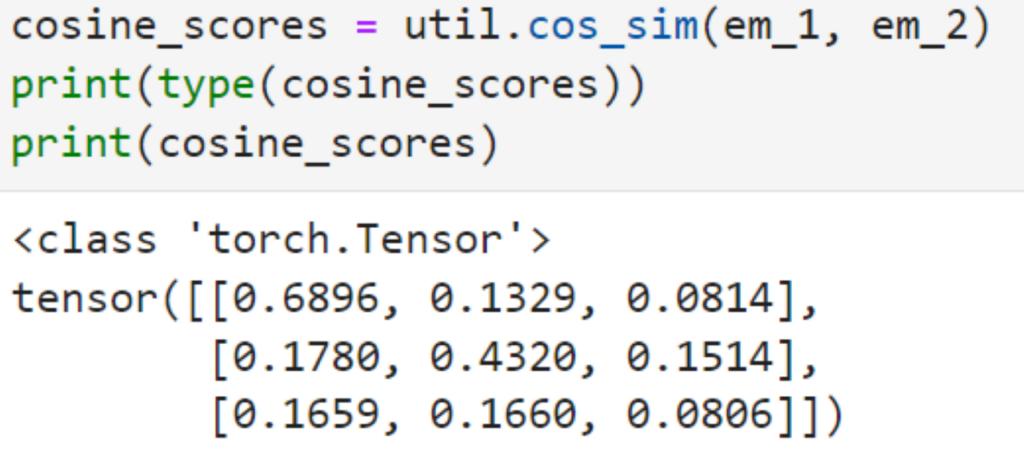
Matriisin mukaan listojen ensimmäisten lauseiden samankaltaisuus on 0.6896, keskimmäisten lauseiden samankaltaisuus on 0.4320 ja viimeisten lauseiden samankaltaisuus on vain 0.0806. Samankaltaisuusmatriisin analyysin jälkeen voidaan päättää, että malli toimii onnistuneesti. (Fillion 2022.)
Sentence Transformers -malleilla on monenlaiset sovelluskohteet. Esimerkiksi Ekaterina Ruotsalaisen (2024) opinnäytetyössä, jossa käsiteltiin nimikehallinnan laadunvarmistusta, tätä koneoppimismallia käytettiin nimikeduplikaattien suodattamiseen suuresta datamassasta.
Kirjoittajat
Ekaterina Ruotsalainen on valmistunut LAB-ammattikorkeakoulusta, IoT:stä tekoälyyn -insinöörikoulutusohjelmasta (YAMK). Hänellä on useiden vuosien työkokemus järjestelmätuen ja tuotetiedon hallinnan tehtävistä.
Minna Asplund, TkL, toimii LAB-ammattikorkeakoulussa yliopettajana ja koordinaattorina IoT:stä tekoälyyn -insinöörikoulutuksessa (YAMK).
Lähteet
Fillion, E. 2022. Semantic Similarity With Sentence Transformers. Vennify.ai 8.6.2022. Viitattu 16.4.2024. Saatavissa https://www.vennify.ai/semantic-similarity-sentence-transformers/
Rokon, O. F. 2023. Transformers in NLP: BERT and Sentence Transformers. Medium.com 25.9.2023. Viitattu 17.4.2024. Saatavissa https://medium.com/@mroko001/transformers-in-nlp-bert-and-sentence-transformers-3faab61918ea
Ruotsalainen, E. 2024. Nimikehallinnan laadunvarmistuksen tehostaminen. YAMK-opinnäytetyö. LAB-ammattikorkeakoulu, IoT:stä tekoälyyn -koulutus. Lahti. Viitattu 16.4.2024. Saatavissa https://www.theseus.fi/bitstream/handle/10024/851376/Ruotsalainen_Ekaterina.pdf?sequence=2&isAllowed=y
Tripathy, S. 2024. Exploring Contextual Text Similarity: A Dive into Machine Learning Techniques. Medium.com 5.1.2024. Viitattu 16.4.2024. Saatavissa https://medium.com/@swarup.t/exploring-contextual-text-similarity-a-dive-into-machine-learning-techniques-3d477c88bf20
Van Otten, N. 2022. Top 7 Ways To Implement Document & Text Similarity In Python: NLTK, Scikit-learn, BERT, RoBERTa, FastText and PyTorch. Spot Intelligence 19.12.2022. Viitattu 16.4.2024. Saatavissa https://spotintelligence.com/2022/12/19/text-similarity-python/



{kind=link}
{kind=link}
{kind=link}
{kind=link}