
Työelämässä tekoälyltä odotetaan kahta asiaa yhtä aikaa: sen pitäisi vastata nopeasti mutta myös osua oikeaan. Käytännössä nämä tavoitteet eivät aina toteudu samanaikaisesti. Mitä enemmän järjestelmä käyttää aikaa tiedon hakuun, tulosten monipuolistamiseen ja uudelleenjärjestämiseen, sitä paremmaksi vastaus voi muuttua. Samalla vasteaika kasvaa, laskentaa tarvitaan enemmän ja energiankulutus voi lisääntyä. Datakeskusten sähkönkulutuksen arvioidaan kasvavan voimakkaasti tekoälyn käytön lisääntyessä, mikä tekee myös energiankulutuksesta ja hiilijalanjäljestä osan tekoälyratkaisujen arviointia. (IEA 2025.)
Sama kompromissi näkyy myös tämän hetken tekoälypalveluissa. OpenAI kuvaa GPT-5:tä järjestelmänä, joka osaa vastata nopeasti tai käyttää enemmän aikaa vaikeampiin tehtäviin. Lisäksi OpenAI:n kehittäjäohjeissa korostetaan, että mallivalinta, tuotettujen tokenien määrä ja työvaiheiden määrä vaikuttavat suoraan latenssiin. (OpenAI 2025; OpenAI API 2026.) Käytännössä nopeus, laatu ja kustannus ovat siis sidoksissa toisiinsa. Tämä ei ole vain tekninen kysymys, vaan käytännön kehittämistehtävä organisaatioille, jotka rakentavat generatiivista tekoälyä osaksi työprosessejaan tai tuotteitaan.
Laatu paranee, mutta viive kasvaa
Sama ilmiö näkyy myös Heinosen (2026) opinnäytetyössä, jossa tutkittiin viiveen vaikutusta laatuun Qdrant-vektoritietokantaa hyödyntävässä suomenkielisessä RAG-toteutuksessa. Työssä verrattiin perusvektorihakua ja vektorihakuja, joita monipuolistettiin MMR-menetelmällä, joiden välituloksia uudelleenjärjestettiin ja joista poistettiin kaksoiskappaleita. Tulosten mukaan monipuolistaminen paransi laatua ilman käytännössä merkittävää mediaanilatenssin kasvua. Uudelleenjärjestäminen toi lisähyötyä erityisesti tulosten relevanssiin, mutta samalla sen latenssikustannus oli selvästi suurempi. Erillisessä uudelleenjärjestämismallien vertailussa monikielinen malli tuotti paremman laatutuloksen, kun taas englanninkielinen Cross-Encoder-malli oli selvästi nopeampi.
Työelämän kannalta olennainen viesti näkyy hyvin seuraavassa taulukossa (ks. Taulukko 1), joka kuvaa hakustrategioiden laatu–latenssi-kompromissia selkeästi. Monipuolistaminen parantaa hakutulosten järjestyksen laatua lähes ilman merkittävää lisäviivettä, mutta uudelleenjärjestäminen nostaa laatua vasta selvästi suuremmalla latenssikustannuksella.
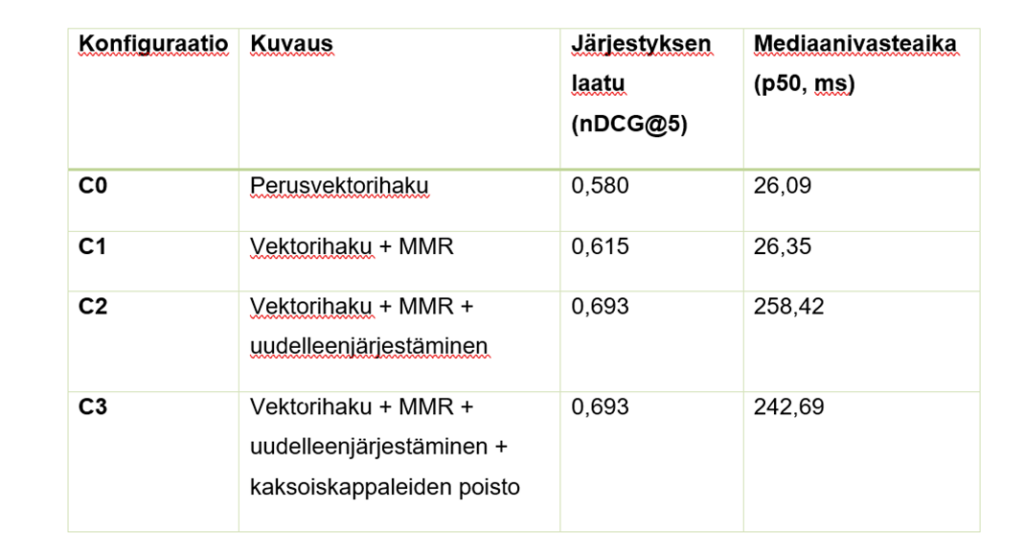
Perusvektorihaun nDCG@5-arvo oli 0,580 ja p50-latenssi 26,09 millisekuntia. Kun hakuun lisättiin MMR-monipuolistaminen, nDCG@5 nousi arvoon 0,615, mutta p50-latenssi pysyi lähes samana. Tämä viittaa siihen, että monipuolistaminen paransi tulosten järjestystä ilman käytännössä merkittävää lisäviivettä. Kun mukaan lisättiin uudelleenjärjestäminen, nDCG@5 nousi selvästi arvoon 0,693, mutta p50-latenssi kasvoi 258,42 millisekuntiin. Kaksoiskappaleiden poisto ei enää parantanut nDCG@5-arvoa, mutta laski p50-latenssia hieman 242,69 millisekuntiin.
Tulokset havainnollistavat, että parempi hakutulos ei ole ilmainen: laadun parantaminen voi vaatia lisälaskentaa ja kasvattaa viivettä. Tässä aineistossa MMR oli kevyt parannus, kun taas uudelleenjärjestäminen toi suurimman laatuhyödyn mutta myös suurimman latenssikustannuksen. (Heinonen 2026.)
Käyttötapaus ratkaisee
Käyttötapaus ratkaisee, millainen hakustrategia on tarkoituksenmukainen. Jos käyttäjä tarvitsee nopeasti suuntaa antavan vastauksen, kevyt vektorihaku tai MMR-monipuolistaminen voi riittää. Jos taas kyse on asiantuntijatyöstä, sopimusanalyysistä tai päätöksenteon tuesta, suurempi viive voi olla hyväksyttävä, jos tulosten relevanssi paranee. Qdrantin dokumentaatio tukee tätä johtopäätöstä: MMR auttaa vähentämään redundantteja hakutuloksia ja lisäämään tulosjoukon monipuolisuutta, kun taas relevanssia parantavat lisävaiheet voivat lisätä laskentaa ja viivettä (Qdrant 2025; Qdrant 2026).
Yrityksille tämä tarkoittaa, ettei kaikkia tekoälypalveluja kannata rakentaa samalla logiikalla. Asiakaspalvelun ensivasteessa tai työntekijän arjen pikakysymyksissä jo pieni lisäviive voi tuntua hitaalta, jolloin kevyempi hakuratkaisu voi olla perusteltu. Sen sijaan tarkkuutta vaativissa käyttökohteissa hitaampi mutta osuvampi vastaus voi tuottaa enemmän arvoa kuin mahdollisimman nopea vastaus.
Tekoälyn käyttöönotossa tärkein kysymys ei siis ole, kumpi on tärkeämpi, laatu vai nopeus. Olennaisempaa on tunnistaa, missä kohdassa työprosessia tarvitaan nopeutta ja missä kohdassa tarkkuutta. Siksi tekoälyratkaisujen kehittämisessä ei riitä, että mitataan vain mallin laatua, vaan samalla on arvioitava vasteaikaa, käyttökustannuksia ja käyttökontekstia.
Kirjoittajat
Karine Heinonen on ohjelmistotekniikan insinööriopiskelija LAB-ammattikorkeakoulussa. Hänen opinnäytetyönsä käsittelee suomenkielisen RAG-järjestelmän tiedonhakustrategioiden vaikutusta hakutulosten laatuun ja suorituskykyyn.
Matti Welin toimii yliopettajana LAB-ammattikorkeakoulussa tieto- ja viestintätekniikan koulutusvastuussa. Hän on kiinnostunut suurista kielimalleista ja niiden käytöstä insinöörityössä erityisesti ICT-alalla. Hän toimi Heinosen opinnäytetyön ohjaajana.
Lähteet
Heinonen, K. 2026. Hakustrategioiden vaikutus suomenkielisen RAG-järjestelmän tiedonhaun laatuun ja suorituskykyyn. Opinnäytetyö. LAB-ammattikorkeakoulu. Viitattu 23.4.2026. Saatavissa https://www.theseus.fi/bitstream/handle/10024/914330/Heinonen_Karine.pdf?sequence=2&isAllowed=y
IEA. 2025. Energy and AI. Executive summary. International Energy Agency. Viitattu 23.4.2026. Saatavissa https://www.iea.org/reports/energy-and-ai/executive-summary
JoshuaWoroniecki. 2020. Kannettava tietokone, Digitaalisen laitteen, Tekniikkaa. Pixabay. Viitattu 20.5.2026. Saatavissa https://pixabay.com/fi/photos/kannettava-tietokone-5673901/
OpenAI. 2025. Introducing GPT-5. Viitattu 23.4.2026. Saatavissa https://openai.com/fi-FI/index/introducing-gpt-5/
OpenAI API. 2026. Latency optimization. Viitattu 23.4.2026. Saatavissa https://developers.openai.com/api/docs/guides/latency-optimization
Qdrant. 2025. Balancing Relevance and Diversity with MMR Search. Viitattu 23.4.2026. Saatavissa https://qdrant.tech/blog/mmr-diversity-aware-reranking/
Qdrant. 2026. Search Relevance. Viitattu 23.4.2026. Saatavissa https://qdrant.tech/documentation/search/search-relevance/




{kind=link}
{kind=link}
{kind=link}
{kind=link}